When I discussed the base implementation of graph datatypes with the NetworkX developers, I was surprised when they told me that they found the current Python dict-of-dict's approach faster than even any C implementations. Perhaps the missing ingredient was Cython, which allowed me to beat out the dicts in under twenty four hours. The underlying implementation is an adjacency list, achieved by an array of custom made hash tables, whose buckets are rudimentary binary trees. There is an option to specify at run time the expected degree of the graph-- these tests were done on random cubic graphs. The vertical axis is number of vertices, the horizontal is a single edge access, in secs x 10000000.
sage: G = graphs.RandomRegular(3,100)

3 comments:
Robert, that is a fricking amazing speed improvement! Awesome job :-)
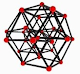
What's that plot off to the right? You know, the black mess?
The black mess is just a picture of one of the test case graphs - a random regular graph.
Post a Comment